Regular Expression yoki RegEx — qidirish uchun ishlatiladigan pattern (belgilar ketma-ketligi). RegEx orqali string ichida ma'lum pattern bor-yo'qligini tekshirish mumkin.
Boshlovchilar uchun RegEx'ni Ctrl+F bilan ishlaydigan oddiy "Search/Find"ning ancha kuchli varianti deb tasavvur qiling. Oddiy qidirish faqat bir xil so'zni topadi, RegEx esa pattern topadi: masalan, juda uzun hujjatda barcha telefon raqamlar, email manzillar yoki sana formatlarini aniq matnni bilmasdan ham topish mumkin.
Dastlab RegEx ko'plab maxsus belgilar sabab chalkash ko'rinadi. Lekin bu texnikani o'zlashtirsangiz, matnni qayta ishlash (text processing) va foydalanuvchi kiritmasini tekshirish (input validation) ishlarida juda katta foydasi tegadi.
Python'da re nomli o'rnatilgan (built-in) modul bor va u Regular Expression bilan ishlashga yordam beradi.
re modulidan foydalanish
Python'da RegEx ishlatish uchun re modulini import qiling:
import re
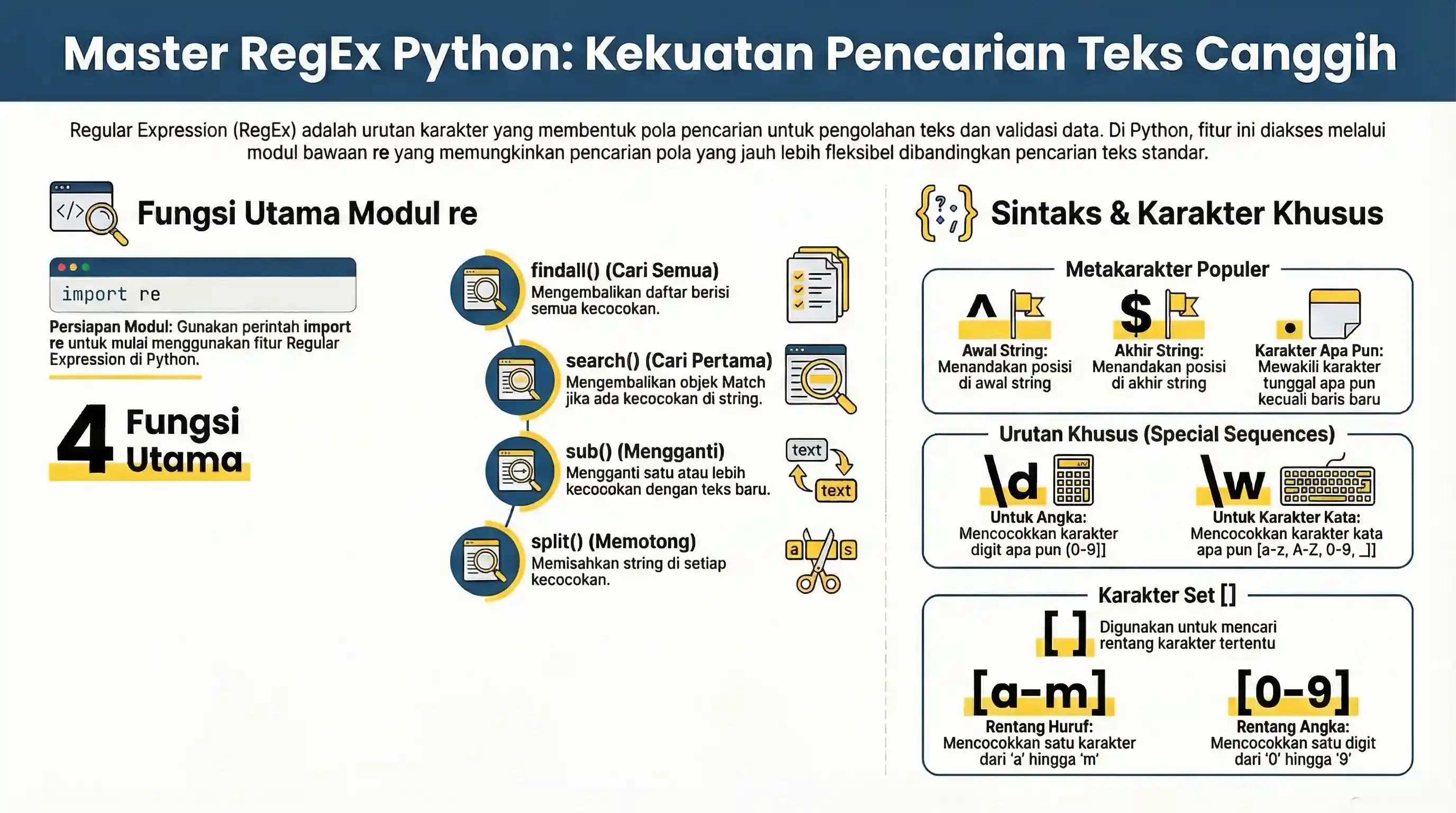
re modulidagi funksiyalar
re moduli string ichidan mosliklarni (match) qidirish uchun funksiyalarni beradi:
| Funksiya | Tavsif |
|---|---|
findall |
Barcha match'larni list qilib qaytaradi |
search |
String ichida istalgan joyda match bo'lsa Match obyekt qaytaradi |
split |
Match topilgan joylarda string'ni bo'lib list qaytaradi |
sub |
Bir yoki bir nechta match'ni boshqa matn bilan almashtiradi |
search() funksiyasi
search() string ichidan match qidiradi va match bo'lsa Match obyekt qaytaradi. Bir nechta match bo'lsa, faqat birinchi topilgani qaytadi.
import re
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if x:
print("YES! We have a match!")
else:
print("No match")
findall() funksiyasi
findall() barcha match'larni list qilib qaytaradi.
import re
txt = "The rain in Spain"
x = re.findall("ai", txt)
print(x)
Match'lar topilgan tartibda listga tushadi. Agar match bo'lmasa, bo'sh list qaytadi.
split() funksiyasi
split() match topilgan joylarda string'ni bo'lib list qaytaradi.
import re
txt = "The rain in Spain"
x = re.split(r"\s", txt)
print(x)
Match sonini maxsplit parametri bilan cheklash mumkin:
import re
txt = "The rain in Spain"
x = re.split(r"\s", txt, maxsplit=1)
print(x)
sub() funksiyasi
sub() match'larni o'zingiz xohlagan matn bilan almashtiradi.
import re
txt = "The rain in Spain"
x = re.sub(r"\s", "9", txt)
print(x)
Almashtirishlar sonini count parametri bilan boshqarish mumkin:
import re
txt = "The rain in Spain"
x = re.sub(r"\s", "9", txt, count=2)
print(x)
Metacharacter'lar
Metacharacter'lar — maxsus ma'noga ega belgilar:
| Belgi | Tavsif | Misol |
|---|---|---|
[] |
Belgilar to'plami | "[a-m]" |
\ |
Maxsus ketma-ketlikni bildiradi (yoki maxsus belgilarni escape qilish uchun) | "\d" |
. |
Istalgan belgi (newline'dan tashqari) | "he..o" |
^ |
Shu bilan boshlanadi | "^hello" |
$ |
Shu bilan tugaydi | "world$" |
* |
0 yoki undan ko'p marta takrorlanish | "aix*" |
+ |
1 yoki undan ko'p marta takrorlanish | "aix+" |
{} |
Aniq ko'rsatilgan marta takrorlanish | "al{2}" |
| |
Yoki (either/or) | "falls|stays" |
() |
Tutib olish (capture) va guruhlash |
Maxsus ketma-ketliklar
Special sequence — \ dan keyin keladigan maxsus belgi bo'lib, alohida ma'noga ega:
| Belgi | Tavsif | Misol |
|---|---|---|
\A |
Belgilar string boshida bo'lsa match qaytaradi | "\AThe" |
\b |
Belgilar so'z boshida yoki so'z oxirida bo'lsa match qaytaradi | r"\bain" r"ain\b" |
\B |
Belgilar so'z boshi/oxirida EMAS, lekin so'z ichida bo'lsa match qaytaradi | r"\Bain" r"ain\B" |
\d |
String ichida raqam bo'lsa match qaytaradi (0-9) | "\d" |
\D |
String ichida raqam bo'lmasa match qaytaradi | "\D" |
\s |
String ichida whitespace bo'lsa match qaytaradi | "\s" |
\S |
String ichida whitespace bo'lmasa match qaytaradi | "\S" |
\w |
String ichida word characters bo'lsa match qaytaradi (a-Z, 0-9 va _) |
"\w" |
\W |
String ichida word characters bo'lmasa match qaytaradi | "\W" |
\Z |
Belgilar string oxirida bo'lsa match qaytaradi | "Spain\Z" |
Set'lar
Set — [] ichidagi belgilar to'plami bo'lib, maxsus ma'noga ega:
| Set | Tavsif |
|---|---|
[arn] |
a, r yoki n dan biri bor bo'lsa match |
[a-n] |
a dan n gacha bo'lgan kichik harflardan biri bo'lsa match |
[^arn] |
a, r, n dan tashqari istalgan belgi bo'lsa match |
[0123] |
0, 1, 2 yoki 3 dan biri bo'lsa match |
[0-9] |
0 dan 9 gacha bo'lgan raqam bo'lsa match |
[0-5][0-9] |
00 dan 59 gacha bo'lgan ikki xonali son bo'lsa match |
[a-zA-Z] |
a dan z gacha yoki A dan Z gacha bo'lgan harf bo'lsa match |
[+] |
Set ichida +, *, ., |, (), $, {} maxsus ma'noga ega emas. [+] string ichidagi + belgisini match qiladi |
Misol
import re
# a dan n gacha bo'lgan kichik harflarni topish
x = re.findall("[a-n]", txt)
print(x)
Agar match topilmasa, findall() bo'sh list qaytaradi.